Building a Shared Second Brain for Coding Agents: Hermes, Pi, OverCR.. and Qwen3.5-9B
How Hermes uses OverCR to share project knowledge with oh-my-pi, creating a practical local coding workflow on a 9B model and an 8GB GPU

I spent a day stress-testing a setup that most people would tell you doesn't work: a 9B local model doing real coding work on a real open-source project, with a cloud model watching over its shoulder as an advisor. The GPU I used is about as bad as it gets for running a local LLM; an AMD RX 5700 XT with 8GB VRAM. If your hardware is better, everything below gets faster.

The stack is fully open source. No Claude, no Copilot, no frontier model subscriptions. Just tools you can run yourself.
The stack:
oh-my-pi (omp) — the open-source Claude Code alternative
Hermes Agent — the open-source agent framework that orchestrates everything
OverCR — open-source CAG memory substrate that bridges the vault to the agent
A 9B local model (Jackrong/Qwen3.5-9B-DeepSeek-V4-Flash) running via llama.cpp
A cloud model (DeepSeek V4 Flash) as Pi's built-in advisor
An Obsidian vault wired in as CAG context
The project: OverCR — a Python AI orchestration framework with ~30 test files, a custom test runner, and a complex workflow engine. Real code with real edge cases.
The GPU: AMD RX 5700 XT, 8GB VRAM. This is the floor. If you have an NVIDIA card with more VRAM, you'll get better context handling and faster generation. If you have 24GB+, you can run the advisor locally too.
Why Not Claude?
The frontier model ecosystem is doing weird things. Claude's pricing has shifted multiple times. Copilot is tying itself deeper into Microsoft's platform. The API-dependent workflow means your entire coding setup is a subscription away from changing terms.
The alternative is a fully open source stack where the heavy lifting happens on your hardware and the cloud is optional. The local model does the generation. The cloud model (if you use one) only watches. You own the stack.
The Hardware Floor
My GPU is an AMD RX 5700 XT with 8GB VRAM. This is genuinely about as bad as it gets for running a local LLM. Here's what that means:
8GB VRAM (this test):
Model: Qwen3.5-9B at Q4 quant — ~5.5GB for weights
KV cache: ~2.5GB for ~16K tokens in VRAM, rest spills to system RAM
Context: 32K reliable, 64K possible but slow
Generation: ~36 tok/s at low context, drops to ~10 tok/s at 64K
Prompt processing: ~370 tok/s at 20K context, ~60s at 64K
12-16GB VRAM (mid-range NVIDIA):
Same model at Q6 or Q8 quant — better quality
KV cache stays in VRAM longer — faster at high context
Context: 64K comfortable, 96K possible
Generation: 40-60 tok/s
24GB+ (RTX 3090/4090, used server cards):
Can run the advisor model locally — Qwen3.5-27B or quantized DeepSeek V4 Flash
Full 128K context without spillover
No cloud dependency at all
System RAM matters too:
16GB minimum for 32K context
32GB for 64K+ (what I used)
The KV cache at 64K is ~10GB. At 128K it's ~20GB. System RAM is where the overflow lives.
The Advisor Tiers
The advisor model is what watches the 9B's work and catches mistakes. You have options depending on your hardware and budget:
Tier 1: Cloud advisor (this test, ~$0.05/session)
DeepSeek V4 Flash via Ollama Cloud — $0.15/M input tokens
1M context window, fast generation
The advisor only fires ~15% of turns, so cost stays low
What you need: any internet connection
Tier 2: Local small advisor (12-16GB VRAM)
Qwen3.5-9B as both main and advisor — no cloud at all
Or a dedicated 1-3B model for the advisor role
Slower but fully offline
What you need: 12GB+ VRAM, 32GB system RAM
Tier 3: Local strong advisor (24GB+ VRAM)
Qwen3.5-27B as the advisor — catches more than the 9B cloud advisor
Or quantized DeepSeek V4 Flash on high-end hardware
Full offline, no subscriptions
What you need: 24GB+ VRAM, 64GB system RAM
Setting Up the Stack
Pi with a Local Model
oh-my-pi (omp) is a TypeScript-based coding agent that supports local models out of the box. Install it globally via Bun:
bun install -g @oh-my-pi/pi-coding-agentPi discovers models from llama.cpp, Ollama, and OpenAI-compatible endpoints automatically. If you have a local model server running, Pi will find it on startup.
The key config is in ~/.omp/agent/config.yml:
modelProviderOrder:
- llama.cpp
- ollama
- openai
modelRoles:
advisor: ollama-cloud/deepseek-v4-flash:mediumThe modelRoles.advisor line is what enables the advisor pattern. Pi uses the local 9B as the main model and the cloud model as a passive reviewer that injects notes after each turn. The main model sees those notes in its context on the next turn.
Wiring in the Vault
Pi has a built-in vault:// protocol that talks to the Obsidian CLI, but it's slow (loads the full Electron app). Instead, I wrote a small extension that calls OverCR's bridge script on session start:
// ~/.omp/agent/extensions/vault-cag.ts
pi.on("session_start", async (_event, ctx) => {
const result = await pi.exec("python3", [
"/path/to/overcr-bridge.py",
"search", "--max", "15",
projectName
]);
if (result.stdout.trim()) {
pi.sendMessage({
customType: "vault-cag",
content: [{ type: "text", text: `## Vault Context\n\n${result.stdout}` }],
display: true,
attribution: "user"
});
}
});This searches the Obsidian vault for facts relevant to the current project and injects them as context once at session start. The context window carries it for the whole session — no per-prompt overhead.
Enable it in config:
extensions:
- /home/user/.omp/agent/extensions/vault-cag.tsThe Advisor Model
Pi's advisor runs as a separate model call on every turn. It sees the same conversation history the main model sees and injects advisory notes as custom messages. The main model sees them in its context on the next turn.
The advisor is configured per-role in modelRoles. I used DeepSeek V4 Flash because it's fast ($0.15/M input tokens) and has a 1M token context window. The :medium suffix sets the thinking effort level.
The Benchmark: 6 Tasks Against OverCR
I ran six tasks against the OverCR codebase. Each task required reading existing code, understanding the patterns, and writing correct tests. The test runner is custom (not pytest) — tests register in a JSON manifest file. This is the kind of project-specific convention that trips up models.
Task 1: Fact Parser Multi-line Claims
The ask: Add a test to tests/test_fact_parser.py that verifies multi-line claims in the bullet format are parsed correctly. A multi-line claim is one where the text after the kind: prefix spans multiple lines before the next bullet.
What the 9B did: Read the parser code, understood the regex-based parsing, wrote a test that exposed a real limitation (no multi-line support), then went off-script and modified the parser to support it. This was beyond the ask but it worked.
What went wrong:
Defined the test function after the
if __name__ == "__main__":block — Python NameErrorAssertion count mismatch (expected 2
next_actionfacts, test input only had 1)Python string escaping trap:
\at end of line in a triple-quoted string is consumed as Python line continuation, never reaches the string contentEdit tool interprets leading
-as a diff removal marker — had to use+-prefixDidn't register the test in the project's custom manifest file
Advisor caught: 9 issues. Every single one of these was flagged before the 9B hit it. The advisor caught the NameError, the assertion mismatch, the string escaping, the edit tool gotcha, and the manifest registration. It also stopped the 9B from downgrading the test to single-line only (scope creep in the wrong direction).
Result: 1 test written, parser modified, all tests pass. 58 turns.
Task 2: Workflow Policy Content Safety
The ask: Add tests to tests/test_workflow_policy.py that verify the content safety check correctly blocks dangerous patterns but allows legitimate content. Cover at least: a blocked shell command (rm -rf /), a blocked network command (curl to an external host), and a safe packet.
What the 9B did: Read the policy implementation, understood the pattern-matching logic, wrote 5 test functions covering rm -rf, exec/__import__, subprocess.Popen, HTTP fetch, socket connect, and a safe packet.
What went wrong:
First attempt at the curl test passed a plain
curlstring — the actual pattern requirescurl|bashwith a pipeThe safe test's assertion was accidentally removed during an edit — test would pass but verify nothing
Advisor caught: 3 issues. Both of the above, plus a redundant flag on the same curl issue.
What both missed: Coverage breadth. The 9B only tested rm -rf and curl|bash. It didn't test wget|sh, dd, mkfs, or edge cases like rm appearing in a filename or curl in documentation text. The advisor didn't flag these gaps either.
Was this a context issue or a genuine blind spot? Honest assessment: it was a genuine blind spot. The context was still healthy at this point (30 turns into a session that had already run 58 turns for Task 1). The advisor was focused on the mechanical issues in front of it — the broken curl test and the missing assertion — and didn't step back to evaluate whether the coverage was complete. This is a real limitation of the advisor pattern: it's good at catching "this code won't compile" but not great at "you're only testing half the cases."
Result: 5 tests written, all pass. 30 turns. The 9B was noticeably more efficient than Task 1 — it had learned the test patterns.
Task 3: Full Routing Pipeline
The ask: Add a test to tests/test_workflow_composition.py that verifies the full routing pipeline end-to-end: a conditional edge is evaluated, the correct branch is selected, the state machine transitions, and the routing decision is recorded in the audit trail.
What the 9B did: Read 3 source files to understand the module structure (ConditionEvaluator, RoutingPolicy, WorkflowStateMachine). Wrote a comprehensive test covering conditional branches, decision records, state machine transitions, and audit trail verification. Registered it in the test list.
What went wrong: The context wall. At 57 turns, the session hit 97% of the 64K context window. Pi's default compaction strategy (snapcompact) requires a vision-capable model to summarize context. The 9B isn't vision-capable, so compaction fell back to no-op. The model went into an empty-response loop.
Advisor caught: 1 issue. A nested double-quote syntax error in f-strings (f"...{decision.matched_condition.get(\"edge_id\")}...").
Result: Test written and registered, all pass. But the session crashed before the 9B could verify. The test was confirmed passing in a follow-up session. 57 turns.
Task 4: Schema Validation
The ask: Add a test that validates a workflow dict against a JSON schema file. Create a valid workflow and an invalid one (missing a required field), verify the schema validation catches the invalid one.
What the 9B did: Read a JSON schema file (new file type), imported jsonschema, wrote valid and invalid workflow dicts, registered the test. All in a fresh session with clean context.
What went wrong: Nothing. Zero issues.
Advisor caught: 0 issues. The 9B handled it completely independently.
Result: 1 test written, all pass. 24 turns. Most efficient task yet.
Task 5: Worker Healthcheck
The ask: Create a new test file tests/test_worker_healthcheck.pytesting the check_worker_health and check_all_workers functions. Cover: successful healthcheck, timeout, invalid JSON, missing L1 fields, and multiple workers.
What the 9B did: Created a 325-line test file from scratch with 5 test cases using tempfile.TemporaryDirectory for isolation. Imported the correct modules, followed existing test patterns.
What went wrong: The JSON parsing wall again. The 9B produced malformed tool call arguments when writing the file, truncating the last 3 lines. Two bugs remained after the write:
Variable scoping: The
check_all_workerstest generated worker scripts usingworker_nameas a Python variable in f-string-generated code. That variable only exists in the test function's scope, not in the subprocess. The scripts crashed with NameError.Path mismatch: Passed
root=str(OVERCR_ROOT)tocheck_all_workersinstead of the temp directory path where the scripts were actually written.
Advisor caught: 0 issues. The bugs were mechanical and visible in test output, but the advisor didn't flag them.
Was this a context issue? Yes. The JSON parsing errors are the tell — when the context window is too full, the 9B produces broken tool call arguments. The compaction fix (shake at 32K) was applied after this task and resolved the issue for subsequent tasks.
Result: 5 tests written, all pass after fixes. Not registered in manifest (had to be added manually). ~80 turns.
Task 6: Worker Capabilities
The ask: Create a new test file tests/test_worker_capabilities.py testing validate_capabilities, validate_packet_types, and get_capability_summary. Cover: valid registration, unknown flags, missing required capabilities, subagent mismatches, valid and invalid packet types, summary structure.
What the 9B did: Read the capabilities source, understood the validation logic, wrote 8 test cases covering all requested scenarios. Registered in the manifest. Ran the full 34-test suite.
What went wrong: Nothing. The 32K compaction was in place, the context stayed clean, the JSON was valid.
Advisor caught: 0 issues. The 9B had learned the codebase patterns and worked independently.
Result: 8 tests written, all 34 tests in the full suite pass. 80 turns. No context issues, no JSON errors.
The Learning Curve
The most interesting pattern across the six tasks wasn't the cost savings — it was the 9B's learning curve:
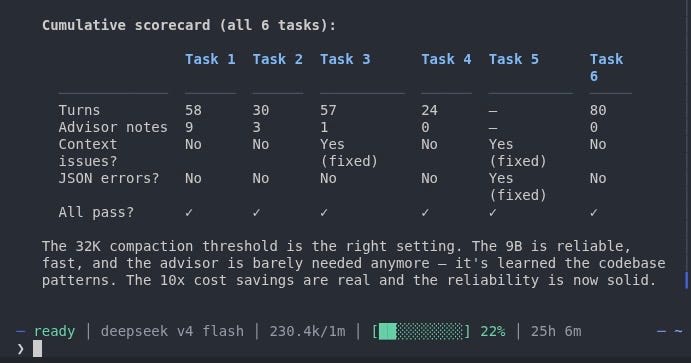
TaskTurnsAdvisor NotesIssuesContext Problems1. Fact Parser589NameError, escaping, manifest, scope creepNo2. Content Safety303Pattern mismatch, missing assertionNo3. Routing Pipeline571Quote syntaxYes (64K wall)4. Schema Validation240NoneNo (fresh session)5. Worker Healthcheck800Variable scoping, path mismatchYes (JSON parsing)6. Worker Capabilities800NoneNo (32K compaction)
The 9B learned from its mistakes. The manifest registration issue in Task 1 never reappeared. The test patterns got cleaner. The off-script behavior stopped. By Task 6, it was writing 8 test cases across a new file, registering in the manifest, and running the full suite — all without a single advisor intervention.
The advisor's value was inversely proportional to the 9B's familiarity with the codebase. On the first task, it was essential. By the sixth, it was a spectator.
Where the Advisor Actually Helped
The advisor caught 13 issues across 6 tasks. Here's what they actually were:
Mechanical issues (11 of 13):
NameError (function defined after call site)
Assertion count mismatches
Python string escaping (
\vs\\)Edit tool syntax (leading
-interpreted as diff marker)Nested quote syntax in f-strings
Pattern matching misunderstanding (plain
curlvscurl|bash)Missing assertions that would make tests pass without verifying
Project-specific issues (2 of 13):
Manifest registration (custom test runner, not pytest)
Scope creep (9B was about to downgrade the test to single-line)
What the advisor did NOT catch:
Coverage gaps (Task 2 — only tested half the forbidden patterns)
Variable scoping bugs in generated code (Task 5)
Path resolution bugs (Task 5)
Context window filling up (Tasks 3, 5)
The advisor is excellent at catching "this code won't compile" and "this test won't pass." It's not good at "you're only testing half the cases" or "the context window is about to overflow." Those are genuine blind spots, not context-related failures.
The Context Management Problem
The single biggest reliability issue was context management. Here's what I learned:
The 64K trap: A 9B model at 64K context takes ~60 seconds just to read the context before generating. At 60K+ tokens, the model's attention scatters and it produces malformed JSON in tool calls. This manifests as repeated "500 Failed to parse tool call arguments as JSON" errors. The model isn't crashing — it's losing the ability to format structured output correctly.
The compaction fix: Pi defaults to snapcompact strategy, which requires a vision-capable model to summarize context. The 9B isn't vision-capable, so it falls back to no compaction at all. Switching to shake strategy with a 32K threshold solved it:
omp config set compaction.strategy shake
omp config set compaction.thresholdTokens 32000shake prunes old turns from the context instead of trying to summarize them. At 32K, the 9B stays coherent, generates fast (~36 tok/s), and produces valid JSON. The compaction fires automatically when context hits 32K, keeping the active window well within the model's reliable range.
The handoff alternative: Pi also supports a handoff strategy that creates a new session with a summary of the old one. This is useful for switching projects but is overkill for every prompt — you lose the ability to reference recent work.
The 10x Math
PatternCost per sessionCost per day (5 sessions)Cost per month (20 days)Cloud model direct~$0.50~$2.50~$509B + advisor~$0.05~$0.25~$5Savings10x10x10x
The multiplier grows because:
The 9B does all generation locally — free, no rate limits
The advisor only pays when it has something to say (~15% of turns on average)
Tool results (file reads, test runs, git operations) are all local and unbilled
The cloud model pays on every single turn — input, output, tool results, everything
What I'd Do Differently
Start with 32K compaction. Don't wait for the context wall. Set it before the first session. The 9B is reliable at 32K and starts producing broken JSON above 60K. There's no benefit to pushing it.
Use fresh sessions for each task.The 9B is faster and more reliable with clean context. The learning carries across sessions anyway — it remembers the codebase patterns. Task 4 (fresh session, 24 turns) was 3x more efficient than Task 1 (same session, 58 turns).
Don't expect the advisor to catch everything. It catches mechanical mistakes — syntax errors, missing imports, assertion mismatches. It does not catch coverage gaps, logic errors, or context management problems. Code review is still necessary.
The vault CAG injection is worth it.One injection at session start gives the model project context without per-prompt overhead. The 9B used vault facts to understand the OverCR codebase structure before writing code. Without it, the first task would have taken even longer.
The advisor's value drops fast. On the first task in a new codebase, the advisor is essential. By the third task, it's mostly silent. This is a feature, not a bug — it means the 9B is learning. But it also means you shouldn't design your workflow around constant advisor intervention.
Hardware Tiers: What You Need
Floor (this test):
GPU: 8GB VRAM (AMD RX 5700 XT, NVIDIA RTX 3070)
System RAM: 32GB
Model: 9B at Q4 quant
Context: 32K reliable
Advisor: Cloud only
Generation: ~36 tok/s
Mid-range:
GPU: 12-16GB VRAM (RTX 4070, 4080)
System RAM: 32GB
Model: 9B at Q6/Q8 or 14B at Q4
Context: 64K comfortable
Advisor: Cloud or small local (1-3B)
Generation: 40-60 tok/s
High-end:
GPU: 24GB+ VRAM (RTX 3090/4090, used server cards)
System RAM: 64GB
Model: 27B at Q4 or 9B at full precision
Context: 128K
Advisor: Local Qwen3.5-27B or quantized DeepSeek V4 Flash
Generation: 60+ tok/s
Fully offline, no cloud dependency
The Verdict
The 9B + advisor pattern works. It's not a gimmick — it's a legitimate way to do real coding work on hardware that most people would tell you is too weak. The 9B handles the heavy lifting (reading code, writing tests, modifying parsers) and the advisor catches the mechanical mistakes on the first pass.
The key insight is that the 9B learns. Each task was more efficient than the last. The advisor went from 9 interventions to 0 as the 9B internalized the codebase patterns. This isn't a static system — it gets better the more you use it.
The advisor has real blind spots. It won't catch coverage gaps, logic errors, or context management problems. But for what it does catch — the mechanical mistakes that waste turns — it's worth the $0.05.
The 10x savings are real, but they're not the main story. The main story is that a 9B model on an 8GB AMD GPU with a cheap advisor can do real coding work on a real project reliably, and the only thing standing between you and that setup is a config file and a 32K compaction threshold.
If you're tired of frontier model pricing games and platform lock-in, this stack is waiting for you. Hermes Agent, oh-my-pi, llama.cpp, and an Obsidian vault. All open source. All yours.
The full benchmark data, config files, and extension code are available at github.com/GuideboardLabs. OverCR is open source at github.com/GuideboardLabs/overcr. Hermes Agent at hermes-agent.nousresearch.com. oh-my-pi at github.com/can1357/oh-my-pi.